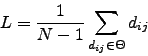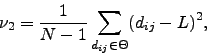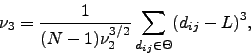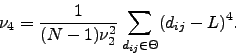The metric distance, introduced by Mantegna [15], is determined from the Euclidean distance between vectors,
![]() . Because
. Because
![]() it follows that:
it follows that:
| (2.23) |
This network (MST) has ![]() links connecting
links connecting ![]() nodes. The nodes represent stocks and the links are chosen such that the sum of all distances (normalised tree length) is minimal. We perform this computation using Prim's algorithm [67]. The Prim's algorithm is given by:
nodes. The nodes represent stocks and the links are chosen such that the sum of all distances (normalised tree length) is minimal. We perform this computation using Prim's algorithm [67]. The Prim's algorithm is given by:
With the information of which stocks are connected to one another, we use the Pajek software to visualise these links [68]. The Pajek software uses the Kamada-Kawai algorithm [69] to display the links and nodes. This algorithm introduce a dynamic system in which every two nodes are connected by a ``spring'' with the respective distance between two stocks. The optimal layout of vertices is when the total spring energy is minimal. As we saw in Figure 1.4 of the Introduction, a MST of stock data is almost organised in clusters of different industrial sectors of the market.
The main idea for using MST, apart of the visualisation of links between companies, is to filter data. From the
![]() correlation coefficients we are only left with
correlation coefficients we are only left with ![]() points, which we believe are the most important coefficients of the correlation matrix.
points, which we believe are the most important coefficients of the correlation matrix.
To see better this clustering property we developed a new kind of tree, where the stocks, if they belong to the same sector and are linked together, emerge in one big node. The sizes of the final nodes are proportional to the number of stocks that they contain, as shown in Figure 2.2.
 |
As we did for the correlations, we study the distribution of distances in the tree and the main moments, as the mean or normalised tree length: